debug attribute does not
guarantee that a document will be logged at all: only if a document goes through the
associated input or output, then it will be logged.
Introduction to the XML Pipeline Definition Language (XPL)
- 1. Introduction
- 2. XPL Interpreter
- 3. Namespace
- 4. <p:config> element
- 5. <p:param> element
- 6. <p:processor> element
- 7. <p:choose> element
- 8. <p:for-each> element
- 9. href attribute
- 9.1. URI
- 9.2. Aggregation
- 9.3. XPointer
- 9.4. Multiple References to an Identifier
- 10. Processor Inputs and Outputs
1. Introduction
The XML Pipeline Definition Language (XPL) is a powerful declarative language for processing XML using a pipeline metaphor. XML documents enter a pipeline, are efficiently processed by one or more processors as specified by XPL instructions, and are then output for further processing, display, or storage. XPL features advanced capabilities such as document aggregation, conditionals ("if" conditions), loops, schema validation, and sub-pipelines.
XPL pipelines are built up from smaller components called XML processors or XML components. An XML processor is a software component which consumes and produces XML documents. New XML processors are most often written in Java. But most often developers do not need to write their own processors because Orbeon Forms comes standard with a comprehensive library. XPL orchestrates these to create business logic, similar to the way Java code "orchestrates" method calls within a Java object.
Please also refer to the XPL 1.0 Submission at W3C.
2. XPL Interpreter
The XPL interpreter is itself implemented as an XML processor, called the Pipeline
processor. This processor reads a pipeline definition following the XPL syntax on
its config input, and assembles a pipeline according to that
definition. It is then able to run the pipeline when called.
3. Namespace
All the elements defined by XPL must be in the namespace with a URI:
http://www.orbeon.com/oxf/pipeline. For consistency, XPL elements
should use the p prefix. This document we will assumes that this prefix
is used.
4. <p:config> element
The root element of a XPL document (config) defines:
-
Zero or more input or output parameters to the pipeline with
<p:param> -
The list of statements that need to executed for this pipeline. A statement
defines either a processor with its connections to other processors in the
pipeline using
<p:processor>, or a condition using<p:choose>.
The <p:config> element and its content are defined in the Relax NG schema with:
<start><ref name="config"/></start><define name="config"><element name="p:config"><optional><attribute name="id"/></optional><ref name="param"/><ref name="statement"/></element></define><define name="statement"><interleave><zeroOrMore><ref name="processor"/></zeroOrMore><zeroOrMore><ref name="choose"/></zeroOrMore><zeroOrMore><ref name="for-each"/></zeroOrMore></interleave></define>
5. <p:param> element
The <p:param> element defines what the inputs and outputs of the
pipeline are. Each input and output has a name. There cannot be two inputs with the
same name or two outputs with the same name, but it is possible to have an output
and an input with the same name. Every input name defines an id that can be later
referenced with the href attribute
such as when connecting processors. The output names can be referenced with the
ref attribute on <p:output>
.

The inputs and outputs of the above pipeline are declared in the XPL document below:
<p:config xmlns:p="http://www.orbeon.com/oxf/pipeline"><p:param type="input" name="data"/><p:param type="input" name="foo"/><p:param type="output" name="bar"/><p:param type="output" name="data"/></p:config>
The <p:param> element and its content are defined in the Relax
NG schema with:
<define name="param"><zeroOrMore><element name="p:param"><interleave><attribute name="name"/><attribute name="type"/></interleave></element></zeroOrMore></define>
6. <p:processor> element
The <p:processor> element places a processor in the pipeline and
connects it to other processors, pipeline inputs, or pipeline outputs.
-
The kind of processor created is specified with the
nameattribute, which is an XML qualified name. A qualified name is composed of two parts:- A prefix: The prefix is mapped to a URI defining a namespace.
- A local name: This name is a name in the namespace defined by the prefix.
This mechanism allows grouping related processors in a namespace. For example, all the basic Orbeon Forms processors are grouped in the
http://www.orbeon.com/oxf/processorsnamespace. This namespace is typically mapped to theoxfprefix. Processors are then referred to using names such asoxf:xsltoroxf:scope-serializer.The name maps to a processor factory. Processor factories are registered through the
processors.xmlfile described in Packaging and Deployment. -
The
<p:input>element connects the input of the processor with the name specified with thenameattribute to one of:-
an inline XML document embedded in the
<p:input>element -
an XML document obtained according to the full
syntax of the
hrefattribute, for example:href="#some-id"href="oxf:/my-document.xml"href="aggregate('document', #some-id, oxf:/my-document.xml#xpointer(/*/*))"
-
an inline XML document embedded in the
-
The
<p:output>element defines anidcorresponding to that output with theidattribute or connects the output to a pipeline output with therefattribute. -
Optionally,
<p:input>and<p:output>can have aschema-hreforschema-uriattribute. Those attributes specify a schema that is used by the Pipeline processor to validate the corresponding input or output.schema-hrefreferences a document using thehrefsyntax.schema-urispecifies the URI of a schema that is mapped to a specific schema in the Orbeon Forms properties file. -
Optionally,
<p:input>and<p:output>can have adebugattribute. When this attribute is present, the document that passes through that input or output is logged to the Orbeon Forms log output. This is useful during development to watch XML documents going through the pipeline.NoteXPL uses a lazy evaluation model, and that having a
The following example feeds an XSLT processor with an inline document and an external stylesheet.
<p:processor name="oxf:xslt"><p:input name="config" href="stylesheet.xsl"/><p:input name="data" schema-href="oxf:/address-book-schema.xml"><address-book><card><name>John Smith</name><email>js@example.com</email></card><card><name>Fred Bloggs</name><email>fb@example.net</email></card></address-book></p:input><p:output name="data" id="address-book"/></p:processor>
The <p:processor> element and its content are defined in the Relax NG schema with:
<define name="processor"><element name="p:processor"><attribute name="name"/><interleave><zeroOrMore><element name="p:input"><attribute name="name"/><ref name="debug"/><ref name="schemas"/><optional><choice><attribute name="href"/><ref name="anyElement"/></choice></optional></element></zeroOrMore><zeroOrMore><element name="p:output"><attribute name="name"/><ref name="schemas"/><ref name="debug"/><choice><attribute name="id"/><attribute name="ref"/></choice></element></zeroOrMore></interleave></element></define>
7. <p:choose> element
The <p:choose> element can be used to execute different
processors depending on a specific condition. The general syntax for this is very
close to XSLT:
<p:choose href="#condition-document"><p:when test="first-condition">...</p:when><p:when test="second-condition">...</p:when><p:otherwise>...</p:otherwise></p:choose>
The conditions are expressed in XPath and operate on the XML document specified by
the href attribute on p:choose. Each branch can contain
regular processor declarations as well as nested conditions.
Outputs declared in a branch are subject to the following conditions:
-
An output id cannot override an output id in scope before the corresponding
chooseelement -
The scope of an output
idis local to the branch if it is connected inside that branch -
The set of output ids not connected inside a branch become visible to
processors declared after the corresponding
chooseelement - The set of output ids not connected inside the branch must be consistent among all branches
The last condition means that if a branch has two non-connected outputs such as output1 and output2, then all other branches must declare the same outputs. On the other hand, inputs in branches do not have to refer to the same outputs.
The <p:choose> element and its content are defined in the Relax
NG schema with:
<define name="choose"><element name="p:choose"><attribute name="href"/><oneOrMore><element name="p:when"><attribute name="test"/><ref name="statement"/></element></oneOrMore><optional><element name="p:otherwise"><ref name="statement"/></element></optional></element></define>
8. <p:for-each> element
With <for-each> you can execute processors multiple times based
on the content of a document. Consider this example: an XML document contains
information about employees, each described in an emp element. This
document is stored in a file called company.xml:
<company><emp><firstname>John</firstname><lastname>Smith</lastname></emp><emp><firstname>Judy</firstname><lastname>Matthews</lastname></emp><emp><firstname>Gloria</firstname><lastname>Schwartz</lastname></emp></company>
You want to apply a stylesheet (stored in transform-employee.xsl) to
each employee. You can do this with the following pipeline:
<p:config xmlns:p="http://www.orbeon.com/oxf/pipeline"><p:for-each href="company.xml" select="/company/emp" root="new-company" id="company-out"><p:processor name="oxf:xslt"><p:input name="data" href="current()"/><p:input name="config" href="transform-employee.xsl"/><p:output name="data" ref="company-out"/></p:processor></p:for-each><!-- The id "company-out" can now be referenced by other --><!-- processor in the pipeline. --></p:config>
This diagram describes how the iteration is done in the above example:
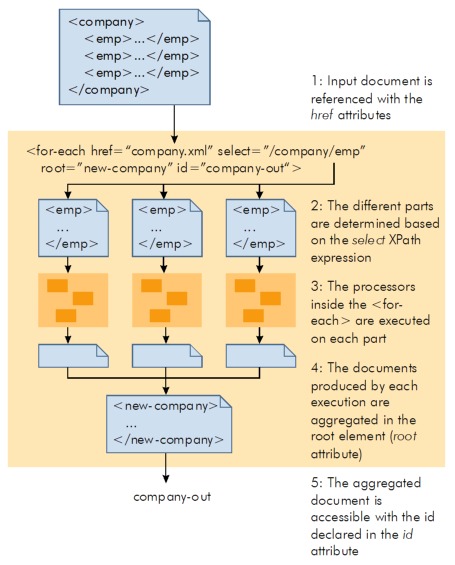
-
In a
<for-each>you can have multiple processors connected together,<choose>statements and nested<for-each>, just like outside of a<for-each>. -
The output of a processor (or other
<for-each>) inside the<for-each>must be "connected to the for-each" using aref="..."attribute. The value in therefattribute must match the value of the<for-each>idattribute. -
You access the current part of the XML document being iterated with
current()in an href expression. If you have nested<for-each>,current()applies to the<for-each>that directly includes thecurrent()expression. -
The processor inside a
<for-each>can access ids declared before the<for-each>statement. -
The aggregated document (the "output of the
<for-each>") is available in the rest of the pipeline with theiddeclared in theidattribute. Alternatively, you can directly connect the output of the<for-each>to an output of the current pipeline with arefattribute (as in the processor<output>element). If therefattribute is used (instead ofid), then the value of therefmust be referenced (instead of the value of theidattribute). When both theidandrefattributes are used, the value of theidattribute must be referenced. -
The
<for-each>can have optional attributes:input-debug,input-schema-href,input-schema-uri,output-debug,output-schema-hrefandoutput-schema-uri. The attributes starting with "input" (respectively "output") work as the similar attributes, just without the prefix, on the<input>element (respectively<output>element). The attributes starting with "input" apply to the document referenced by thehrefexpression. The attributes starting with "output" apply to the output of the<for-each>.
9. href attribute
The href attribute is used to:
- Reference external documents
- Refer outputs of other processors
- Aggregate documents using the aggregate() function
- Select part of a document using XPointer
The complete syntax of the href attribute is
described below in a Backus Nauer Form (BNF)-like syntax:
href ::= ( local_reference | uri | aggregation ) [ xpointer ]
local_reference ::= "#" id
aggregation ::= "aggregate(" root_element_name "," agg_parameter ")"
root_element_name ::= "'" name "'"
agg_parameter ::= href [ "," agg_parameter ]
xpointer ::= "#xpointer(" xpath_expression ")"9.1. URI
The URI syntax is defined in RFC 2396. A URI is used to references an external document. A URI can be:
-
Absolute, if a protocol is specified. For instance
file:/dir/file.xml. -
Relative, if no protocol is specified. For instance
../file.xml. The document is loaded relatively to the URL of the XPL document where thehrefis declared, as specified in RFC 1808.
9.2. Aggregation
Multiple documents can be aggregated with the aggregate() function.
The name of the root element that will contain the aggregated document is
specified in the first argument. The documents to aggregate are specified in the
following arguments. There is no restriction on the number of documents that
can be aggregated.
For example, you have a document (with output id
first):
<employee>John</employee>
And a second document (with output id
second):
<employee>Marc</employee>
Those two documents can be aggregated using aggregate('employees',
#first,
#second). This produces the following document:
<employees><employee>John</employee><employee>Marc</employee></employees>
9.3. XPointer
The XPointer syntax is used to select parts of a document. For example, if you
have a document in a file called company.xml:
<company><name>Orbeon</name><site><web>http://www.orbeon.com/</web><ftp>ftp://ftp.orbeon.com/</ftp></site></company>
The expression company.xml#xpointer(/company/site) produces the
document:
<site><web>http://www.orbeon.com/</web><ftp>ftp://ftp.orbeon.com/</ftp></site>
9.4. Multiple References to an Identifier
The same id may be referenced multiple times in the same XPL document. For
example, the id doc is referenced by two processors in the
following example:
<p:config xmlns:p="http://www.orbeon.com/oxf/pipeline"><p:processor uri="A"><p:output name="data" id="doc"/></p:processor><p:processor uri="B"><p:input name="data" href="#doc"/></p:processor><p:processor uri="C"><p:input name="data" href="#doc"/></p:processor></p:config>
The document seen by B and C are identical. This situation can be graphically represented as:
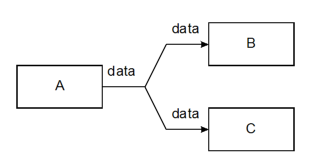
10. Processor Inputs and Outputs
10.1. Declared Inputs and Outputs
XPL processors declare a certain number of inputs and outputs. Those inputs and outputs constitute the interface of the processor, in the same way that methods in object-oriented programming languages like Java expose parameters. For example, the XSLT processor expects:
- a
configinput receiving an XSLT stylesheet definition - a
datainput receiving the XML document to transform - a
dataoutput producing the transformed XML document
You know what inputs and outputs to connect for a given processor by consulting the documentation for that processor. This is similar to looking up a method signature in an object-oriented programming language.
10.2. Connecting Inputs and Outputs
Consider the following XSLT processor instance in a pipeline:
<p:processor name="oxf:xslt"><p:input name="config" href="stylesheet.xsl"/><p:input name="data" schema-href="oxf:/address-book-schema.xml"><address-book><card><name>John Smith</name><email>js@example.com</email></card><card><name>Fred Bloggs</name><email>fb@example.net</email></card></address-book></p:input><p:output name="data" id="address-book"/></p:processor>
Both its config and data inputs are said to be
connected, because the <p:processor> element for the XSLT
processor has <p:input> elements for both those inputs, and they
each refer to an XML document:
- In the first case, a resource called
stylesheet.xsl - In the second case, an inline document with root element
address-book
There are other ways to connect inputs, for example:
<p:config xmlns:p="http://www.orbeon.com/oxf/pipeline"><!-- Pipeline input called "my-input" --><p:param name="my-input" type="input"/><!-- First XSLT transformation --><p:processor name="oxf:xslt"><p:input name="config" href="stylesheet-1.xsl"/><p:input name="data" href="#my-input"/><p:output name="data" id="address-book"/></p:processor><!-- Second XSLT transformation --><p:processor name="oxf:xslt"><p:input name="config" href="stylesheet-2.xsl"/><p:input name="data" href="#address-book"/><p:output name="data" id="phone-list"/></p:processor><!-- ... --></p:config>
In this case:
-
The
datainput of the first XSLT processor instance is connected to themy-inputinput of the pipeline. -
The
datainput of the second XSLT processor instance is connected to theaddress-bookoutput of the first XSLT processor instance.
The example above shows that the address-book output of the first
XSLT processor instance is connected to the input of a following processor. A
processor output can also be connected to a pipeline output, as follows:
<p:config xmlns:p="http://www.orbeon.com/oxf/pipeline"><!-- Pipeline input called "my-input" --><p:param name="my-input" type="input"/><!-- Pipeline output called "my-output" --><p:param name="my-output" type="output"/><!-- XSLT transformation --><p:processor name="oxf:xslt"><p:input name="config" href="stylesheet-1.xsl"/><p:input name="data" href="#my-input"/><p:output name="data" ref="my-output"/></p:processor></p:config>
In this case, the data output of the XSLT processor is connected to
the my-output output of the containing pipeline.
To sum up, a processor input can be connected to:
- a resource XML document
- an inline XML document
- the output of another processor
- a pipeline input
- a combination of the above through the full
syntax of the
hrefattribute
A processor output can be connected to:
- the input of another processor with the
idattribute - a pipeline output with the
refattribute
10.3. Mandatory and Optional Inputs and Outputs
Some inputs and outputs are required by a processor. This means that you
have to declare <p:input> and <p:output>
elements with the appropriate name attribute within the
<p:processor> element corresponding to that processor, and to
connect those inputs and outputs as discussed in the previous section. Most
processors require all their inputs and outputs to be connected.
Some processors on the other hand may declare some inputs and outputs as
optional. This means that the user of the processor may or may not
connect an input or output if it is not necessary to do so. For example, the SQL
processor declares an optional datasource input. If the
datasource input is needed by the user, it must be connected:
<p:processor name="oxf:sql"><p:input name="datasource" href="my-datasource.xml"/><p:input name="data" href="#some-data"/><p:input name="config"><config>...</config></p:input></p:processor>
On the other hand, if the user of the SQL processor does not require an
external datasource document, she can simply not connect the
datasource input:
<p:processor name="oxf:sql"><p:input name="data" href="#some-data"/><p:input name="config"><config>...</config></p:input></p:processor>
It is entirely up to each processor to determine which inputs and outputs are mandatory or optional, and how and when they are read.
Note that a processor may decide whether an input must be connected depending on
the content of other inputs, for example the SQL processor does not require the
datasource input if its config input already refers to
a J2EE datasource. On the contrary, if it does not refer to such a datasource,
it requires the datasource input to be connected. If it is not,
the processor generates an error at runtime.
10.4. Referring to Inputs and Outputs with URIs
In certain cases, the user of a processor must refer, from a processor
configuration, to particular processor inputs and outputs. If you implement a
new processor, you should support the input: and
output: URI schemes for this purpose. On the other hand, if you are
using a standard Orbeon Forms processor supporting such references to
processor inputs and outputs, you can count on the input: and
output: URI schemes being used. For example:
- To refer to a processor input named
my-input, use the URI:input:my-input - To refer to a processor output named
my-output, use the URI:output:my-output
While there is no requirement for processor configurations to follow this URI convention, it is highly recommended to do so whenever possible to ensure consistency. In Orbeon Forms, several processors make use of it, including:
- The XSLT processor
- The XUpdate processor
- The Email processor
For concrete examples, please refer to the XSLT processor or the Email processor documentation.
Currently, no standard processor within Orbeon Forms makes uses of the
output: scheme. The XSLT processor would be a good candidate for
this feature, with XSLT 2.0's support for multiple output documents.