You can compile your processor yourself, or you can use the convenient Java processor which automatically compiles Java code on the fly.
Processor API
- 1. Scope
- 2. Why Write Custom Processors?
- 3. Prerequisites
- 4. Processors With Outputs
- 4.1. Example
- 4.2. Deriving from SimpleProcessor
- 4.3. Declaring Inputs and Outputs
- 4.4. Implementing generate Methods
- 4.5. Reading Inputs
- 4.6. Generating a Document
- 5. Processors With No Output
- 5.1. Implementing The start Method
- 5.2. Example
- 6. Processor State
- 6.1. XPL Program State
- 6.2. XPL Program Cleanup
- 6.3. Processor Instance State
- 7. Using custom processors from XPL
1. Scope
This section documents the Orbeon Forms Processor API. This is a Java API that you can use to write custom processors. You can then use those custom processors in your Orbeon Forms applications, just like the standard processors bundled with Orbeon Forms.
2. Why Write Custom Processors?
In general, Orbeon Forms processors encapsulate logic to perform generic tasks such as executing an XSLT transformation, calling a web service or accessing a database using SQL. With those processors, the developer describes the specifics of a task at a high level in a declarative way.
However, there are cases where:
- no existing processor exactly provides the functionality to be performed
- or, it is more suitable to write Java code to get the job done rather than using an existing processor
In those cases, it makes sense for the developer to write your own processor in Java. This section goes through the essential APIs used to write processors in Java.
Note
3. Prerequisites
Writing Orbeon Forms processors is expected to be done by Java developers who are comfortable with the Java language as well as compiling and deploying onto servlet containers or J2EE application servers. In addition, we assume that the developer is comfortable with either:
4. Processors With Outputs
4.1. Example
We consider a very simple processor with an input
number and an output double. The processor
computes the double of the number it gets as an input. For
instance, if the input is
<number>21</number>, the output will be
<number>42</number>.

import org.orbeon.oxf.pipeline.api.PipelineContext;
import org.orbeon.oxf.processor.SimpleProcessor;
import org.orbeon.oxf.processor.ProcessorInputOutputInfo;
import org.xml.sax.ContentHandler;
import org.xml.sax.SAXException;
import org.xml.sax.helpers.AttributesImpl;
import org.dom4j.Document;
public class MyProcessor extends SimpleProcessor {
public MyProcessor() {
addInputInfo(new ProcessorInputOutputInfo("number"));
addOutputInfo(new ProcessorInputOutputInfo("double"));
}
public void generateDouble(PipelineContext context,
ContentHandler contentHandler)
throws SAXException {
// Get number from input using DOM4J
Document numberDocument = readInputAsDOM4J(context, "number");
String numberString = (String)
numberDocument.selectObject("string(/number)");
int number = Integer.parseInt(numberString);
String doubleString = Integer.toString(number * 2);
// Generate output document with SAX
contentHandler.startDocument();
contentHandler.startElement("", "number", "number",
new AttributesImpl());
contentHandler.characters(doubleString.toCharArray(), 0,
doubleString.length());
contentHandler.endElement("", "number", "number");
contentHandler.endDocument();
}
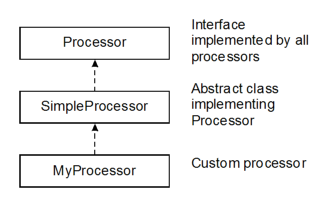
}4.2. Deriving from SimpleProcessor
All the processors must implement the Processor
interface (in the package
org.orbeon.oxf.pipeline.processors).
SimpleProcessor is an abstract class that implements all
the methods of Processor and that can be used as a base
class to create a custom processor (MyProcessor.java in
the figure below).
4.3. Declaring Inputs and Outputs
The processor must declare its mandatory static inputs and outputs. This is done in
the default constructor by calling the addInputInfo and
addOutputInfo methods and passing an object of type
ProcessorInputOutputInfo. For instance:
public MyProcessor() {
addInputInfo(new ProcessorInputOutputInfo("number"));
addOutputInfo(new ProcessorInputOutputInfo("double"));
}
In addition to the name of the input/output, one can pass an optional schema URI declared in the Orbeon Forms properties. If a schema URI is specified, the corresponding input or output can be validated.
Note
Note that the processor may have optional inputs and outputs, and/or read
dynamic inputs and generate dynamic outputs, in which case it doesn't need
to declare such inputs with addInputInfo and
addOutputInfo.
4.4. Implementing generate Methods
For each declared output, the class must declare a corresponding
generate method. For instance, in the example, we have an
output named double. The document for this output is
produced by the method generateDouble.
generate methods must have two arguments:
- A
PipelineContext. This context needs to be passed to other methods that need one, typically to read inputs (more on this later). - A
ContentHandler. This is a SAX content handler that receives the document produced by thegeneratemethod.
4.5. Reading Inputs
If the output depends on the inputs, one will need to read those inputs. There are 3 different APIs to read an input:
- One can get the W3C
DOM representation of the input document by calling
the
readInputAsDOM(context, name)method. - One can get the DOM4J
representation of the input document by calling the
readInputAsDOM4J(context, name)method. - One can provide a custom SAX
content handler to the method
readInputAsSAX(context, name, contentHandler).
Depending on what the generate method needs to
do with the input document, one API might be more appropriate
than the others.
In our example, we want to get the value inside the
<number> element. We decided to go with the
DOM4J API, calling the
numberDocument.selectObject("string(/number)") on
the DOM4J document.
4.6. Generating a Document
The output document can alternatively be generated by:
- Directly calling methods of the content handler
received by the
generatemethod. This is what we do in the example detailed in this section. Here is the code generating the output document: - Create a DOM4J document and have it sent to the content
handler using a
LocationSAXWriter(in packageorg.orbeon.oxf.xml.dom4j):
contentHandler.startDocument();
contentHandler.startElement("", "number", "number",
new AttributesImpl());
contentHandler.characters(doubleString.toCharArray(), 0,
doubleString.length());
contentHandler.endElement("", "number", "number");
contentHandler.endDocument();
Document doc = ...; LocationSAXWriter saxWriter = new LocationSAXWriter(); saxWriter.setContentHandler(contentHandler); saxWriter.write(doc);
Note
Using the LocationSAXWriter provided with Orbeon Forms
is the preferred way to write a DOM4J document to a SAX content handler. The
standard JAXP API (calling
transform with a
org.dom4j.io.DocumentSource) can also be used, but if it
is used, the location information stored in the DOM4J document will be lost.
- Create a W3C document and send it to the content handler using the standard JAXP API:
Document doc = ...; Transformer identity = TransformerUtils.getIdentityTransformer(); transformer.transform(new DOMSource(doc), new SAXResult(contentHandler));
Note
TransformerUtils is a Orbeon Forms class (in package
org.orbeon.oxf.xml). It will create and cache the
appropriate transformer factory. The developer is of course free to
create its own factory and transformer calling directly the JAXP API.
5. Processors With No Output
5.1. Implementing The start Method
Implementing a processor with no output is very similar to implementing a
processor with outputs (see above). The only difference is that you need to
implement the start() method, instead of the
generate() methods.
5.2. Example
The processor below reads its data input and
writes the content of the XML document to the standard output
stream.
package org.orbeon.oxf;
import org.dom4j.Document;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
import org.orbeon.oxf.common.OXFException;
import org.orbeon.oxf.processor.ProcessorInputOutputInfo;
import org.orbeon.oxf.processor.SimpleProcessor;
import org.orbeon.oxf.pipeline.api.PipelineContext;
import java.io.IOException;
import java.io.StringWriter;
public class SystemOutProcessor extends SimpleProcessor {
public SystemOutProcessor() {
addInputInfo(new ProcessorInputOutputInfo("data"));
}
public void start(PipelineContext context) {
try {
Document dataDocument = readInputAsDOM4J(context, "data");
OutputFormat format = OutputFormat.createPrettyPrint();
format.setIndentSize(4);
StringWriter writer = new StringWriter();
XMLWriter xmlWriter = new XMLWriter(writer, format);
xmlWriter.write(dataDocument);
xmlWriter.close();
System.out.println(writer.toString());
} catch (IOException e) {
throw new OXFException(e);
}
}
}
6. Processor State
6.1. XPL Program State
A PipelineContext object is passed by the XPL engine to the
start(), ProcessorOutput.readImpl() and
generateXxx() methods.
The PipelineContext object is used to store information that must
be kept for the entire execution of the current XPL program. This information
is:
- Reset everytime the XPL program is run
- Separate for multiple concurrent executions of an XPL program.
- Shared among all the processors run during the XPL program's execution, including multiple instances of a given processor.
Use the following methods of PipelineContext to store XML program
state:
/** * Set an attribute in the context. * * @param key the attribute key * @param o the attribute value to associate with the key */ public synchronized void setAttribute(Object key, Object o);
/** * Get an attribute in the context. * * @param key the attribute key * @return the attribute value, null if there is no attribute with the given key */ public Object getAttribute(Object key);
6.2. XPL Program Cleanup
You can register a listener on the PipelineContext object to
perform clean-up upon the termination of the XML program, using the following
API:
/** * Add a new listener to the context. * * @param listener */ public synchronized void addContextListener(ContextListener listener);
/**
* ContextListener interface to listen on PipelineContext events.
*/
public interface ContextListener {
/**
* Called when the context is destroyed.
*
* @param success true if the pipeline execution was successful, false otherwise
*/
public void contextDestroyed(boolean success);
}
/**
* ContextListener adapter class to faciliate implementations of the ContextListener
* interface.
*/
public static class ContextListenerAdapter implements ContextListener {
public void contextDestroyed(boolean success) {
}
}
You can register a listener as follows:
pipelineContext.addContextListener(new ContextListenerAdapter() {
public void contextDestroyed(boolean success) {
// Implement your clean-up code here
}
);
Examples of clean-up operations include:
- Performing commits or rollbacks on external resources
- Freeing-up external resources allocated for the execution of the XPL program only
6.3. Processor Instance State
Processors with multiple outputs often have to perform some task when the first output is read, store the result of the task, and then make it available to the other outputs when they are read. This information is:
- Reset everytime the XPL program is run.
- Separate for every processor instance.
-
Shared between calls of the
start(),ProcessorOutput.readImpl()andgenerateXxx()of a given processor instance, during a given XPL program execution..
The PipelineContext methods are not sufficient for this purpose.
In order to store state information tied to the current execution of the current
processor, and shared across the current processor's initialization as well as
outputs reads, use the following methods:
/** * This method is used by processor implementations to store state * information tied to the current execution of the current processor, * across processor initialization as well as reads of all the * processor's outputs. * * This method should be called from the reset() method. * * @param context current PipelineContext object * @param state user-defined object containing state information */ protected void setState(PipelineContext context, Object state);
/** * This method is used to retrieve the state information set with setState(). * * This method may be called from start() and ProcessorOutput.readImpl(). * * @param context current PipelineContext object * @return state object set by the caller of setState() */ protected Object getState(PipelineContext context);
You initialize the processor state in the reset() method, as follows:
public void reset(PipelineContext context) {
setState(context, new State());
}
Where you define class State as you wish, for example:
private static class State {
public Object myStuff;
...
}
You can then obtain your execution state by calling the getState()
method:
State state = (State) getState(context);
You call getState() from the start(),
ProcessorOutput.readImpl() or generateXxx().
7. Using custom processors from XPL
In order to use a custom processor compiled and deployed within Orbeon Forms (as one or more
class files or JAR files), its main class (the one that implements the
Processor interface) must be mapped to an XML qualified name. You do
this mapping in a file called custom-processors.xml under the
config directory. This is an example illustrating the format of the
file:
<processors xmlns:my="http://my.company.com/ops/processors"><processor name="my:processor"><class name="com.company.my.MyOtherProcessor"/></processor><processor name="my:system-out"><class name="com.company.my.SystemOutProcessor"/></processor></processors>
You choose your own prefix name and namespace URI for that prefix, in this example
my and http://my.company.com/ops/processors respectively.
There is no strict format for the namespace URI, but it should identify your company
or organization, here with my.company.com.
Do the mapping on the processors element as usual in XML with:
xmlns:my="http://my.company.com/ops/processors"
You use processors in XPL using the same qualified names used in
custom-processors.xml:
<p:processor name="my:system-out">...</p:processor>
It is important to declare the namespace mapping in
custom-processors.xml as well as in the XPL programs that use those
processors.
There is no constraint to use a single namespace: you may declare multiple namespaces to categorize processors. Using one namespace per company or organization is however the recommended option for convenience.